
1. Software-Defined Vehicles and Cloud Native Computing
|
Developing a service-oriented software platform for software-defined vehicles based on SOAFEE and SOME/IP
|
|
 |
Software-defined vehicles (SDVs) have emerged as a core enabling technology for future mobility. Their ultimate success depends on the implementation of Service-Oriented Architecture (SOA). SOA is a software development/operation methodology that separates various functions of a system into service units, connects them on a network, and builds and operates them as a system. SOA began in the enterprise computing field, and its usefulness has been proven in terms of system agility, interoperability between components and systems, deployment flexibility, and reusability.
Although SOA is essential for SDVs, enterprise computing SOA technology cannot be directly applied to vehicular systems since it does not consider the functional safety of the underlying system. A software platform for SDVs must guarantee the verified performance of services along with the dynamic distribution of services.
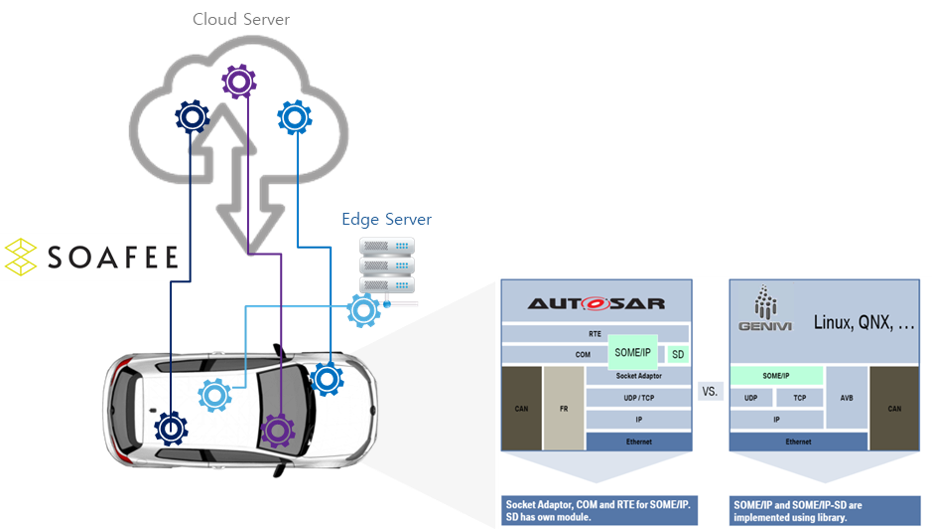
The AUTOSAR Adaptive Platform (AP) has been proposed in the automotive industry, as an industry-strength SOA platform for SDVs. While AP is currently receiving a lot of attention in the automotive industry, it has functional and non-functional limitations that have not yet been resolved as an SDV runtime platform. Additionally, AP was presented as an independent standard within the automotive industry, and thus it has shortcomings in terms of openness for cloud native computing. Consequently, open source-based software platforms for SDVs are actively underway. The related projects attempt to define architecture standards in a code-first manner based on open sources such as Kubernetes and Docker.
At RTOSLab of SNU, to build the foundation for an open, cloud native SDV runtime platform, we develop a SOAFEE-based PoC (proof-of-concept) system using Kubernetes and Docker. To this end, we integrate SOME/IP into SOAFEE and implement it on a hardware testbed that models a centralized zonal E/E architecture.
|
|
Enhancing SOME/IP for real-time communications
|
|
 |
SOME/IP is communication middleware that supports service-oriented communications and is one of the core technologies of the software platform for SDVs. But SOME/IP has four inherent limitations that can restrict its use in SDVs: (1) bounded message transfer latency, (2) limited throughput for huge data transfers, (3) unbounded boot time of a service instance, and (4) unbounded service discovery time.
We conduct research to quantitatively measure these problems in SOME/IP, locate bottleneck points within the protocol stack, and systematically improve them.
|
|
System software supporting on-device AI
|
|
 |
|
2. Kernel Techniques for Active Resource Management
|
Reducing memory interference latency of safety-critical applications via memory request throttling and Linux cgroup
|
|
 |
With the advent of high-performance multicore processors that operate under a limited power budget, dedicated low-end microprocessors with different levels of criticality are rapidly consolidated into a mixed-criticality system. One of the major challenges in designing such a mixed-criticality system is to tightly control the amount of resource contention for a critical application by effectively limiting its performance interference incurred due to sharing resources with non-critical tasks. We propose application-aware dynamic memory request throttling to reduce the memory interference latency of a critical application in a dual criticality system. Our approach carefully differentiates critical task instances from normal task instances and groups them into the critical and normal cgroup, respectively. It then predicts the occurrence of excessive memory contention under critical task execution and then throttles memory requests generated by the normal cgroup via the CPUFreq governor when necessary.
|
3. Linux Kernel Scheduling for Symmetric/Asymmetric Multicore Systems
|
Providing fair-share scheduling in single-ISA asymmetric multicore architecture via scaled virtual runtime and load redistribution
|
|
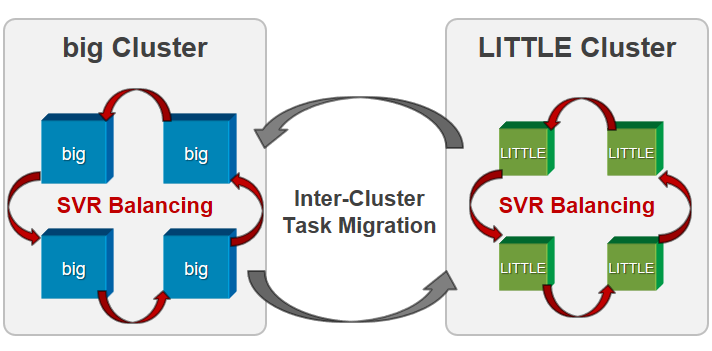 |
Performance-asymmetric multicore processors have been increasingly adopted in embedded systems due to their architectural benefits in improved performance and power savings. While fair-share scheduling is a crucial kernel service for such applications, it is still at an early stage with respect to performance-asymmetric multicore architecture. We first propose a new fair-share scheduler by adopting the notion of scaled CPU time that reflects the performance asymmetry between different types of cores. Using the scaled CPU time, we revise the virtual runtime of the completely fair scheduler (CFS) of the Linux kernel, and extend it into the scaled virtual runtime (SVR). In addition, we propose an SVR balancing algorithm that bounds the maximum SVR difference of tasks running on the same core types. The SVR balancing algorithm periodically partitions the tasks in the system into task groups and allocates them to the cores in such a way that tasks with smaller SVR receive larger SVR increments and thus proceed more quickly.
|
|
Providing fair-share scheduling on symmetric multicore computing systems via progress balancing
|
|
|
Performance isolation in a scalable multicore system is often attempted through periodic load balancing paired with per-core fair-share scheduling. Unfortunately, load balancing cannot guarantee the desired level of multicore fairness since it may produce unbounded differences in the progress of tasks. In reality, the balancing of load across cores is only indirectly related to multicore fairness. To address this limitation and ultimately achieve multicore fairness, we propose a new task migration policy we name progress balancing, and present an algorithm for its realization. Progress balancing periodically distributes tasks among cores to directly balance the progress of tasks by bounding their virtual runtime differences. In doing so, it partitions runnable tasks into task groups and allocates them onto cores such that tasks with larger virtual runtimes run on a core with a larger load and thus proceed more slowly.
|
|
4. Programming Language and Runtime for Future Autonomous Vehicles
|
Splash: stream processing language for real-time and embedded AI
|
|
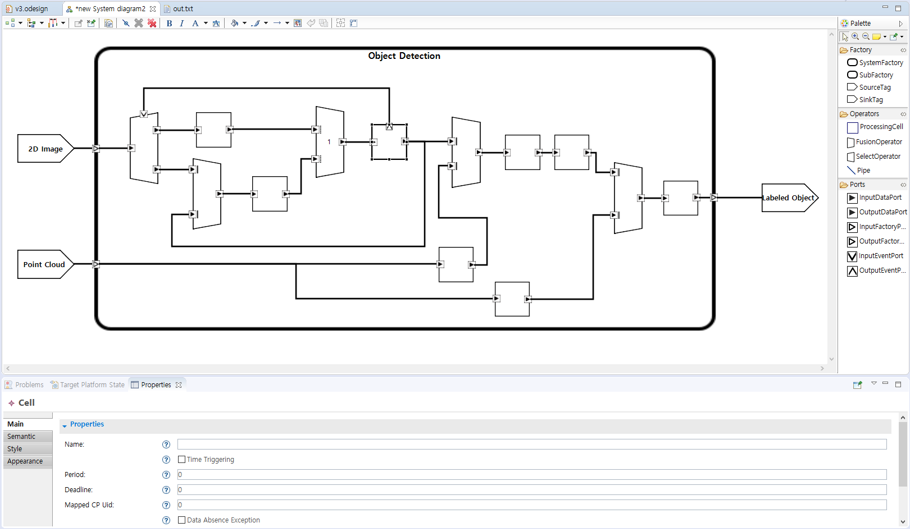 |
In order to fully support Automotive AI, it is necessary to technically address the extra requirements that arise differently from those of conventional vehicles. Two of the most important requirements of Automotive AI are (1) real-time stream processing and (2) reliability. Currently, most companies and research institutes that develop autonomous vehicles rely on application developers to meet the above requirements. Since application developers often resort to a time consuming and iterative tuning process, this approach leads to inefficiencies in the development process and can lead to fatal injuries due to unintended circumstances that are overlooked during the tuning process. To overcome the limitation of the traditional development methodology, we propose the stream processing language named Splash. The Splash has five advantages. First, Splash visually expresses the flow of sensor stream data processing so that developers can easily grasp the complex interworking of a given AI program. Second, Splash let developers explicitly annotate the timing constraints of stream processing. Third, Splash allows developers to define exceptions and specify the handling of each exception. Fourth, Splash can describe complex synchronization issues of sensor fusion algorithms more perceptibly. Finally, Splash supports integration between domains that are developed with different programming paradigms such as data-driven and time-driven.
|
|
Runtime SW stack for real-time and embedded AI
|
|
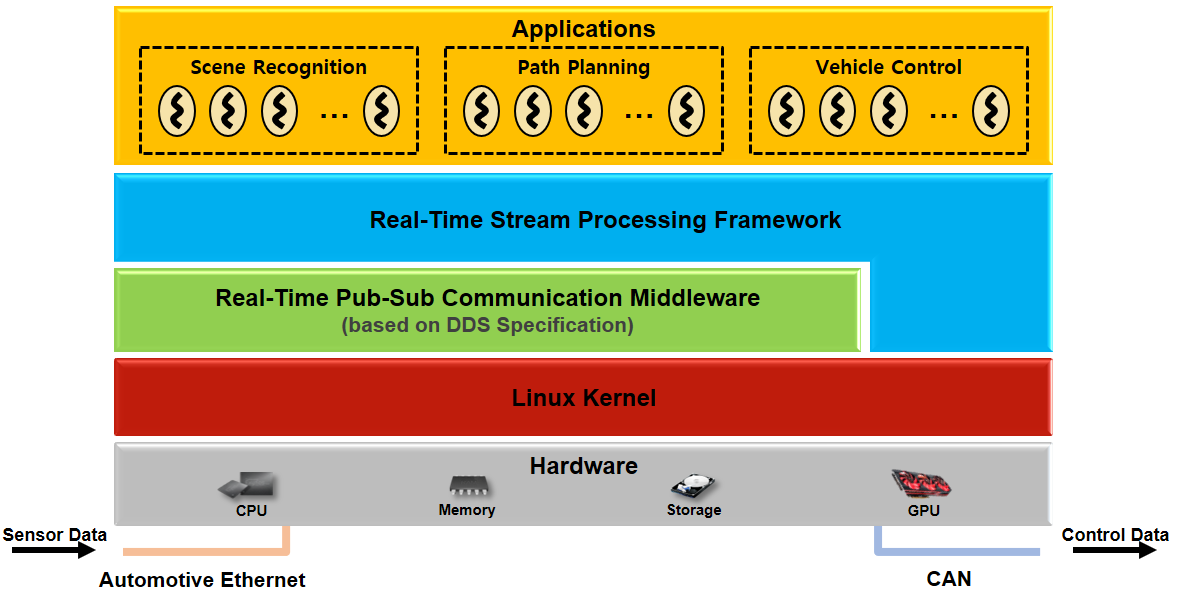 |
We build a runtime software stack that runs real-time and embedded AI applications developed using Splash. The proposed runtime is based on Linux and DDS (Data Distribution Service) that supports real-time publish-subscribe communication. We additionally incorporate Linux kernel optimization techniques in order to meet the non-functional requirements of the real-time and embedded AI applications.
|
5. Operating Systems for Advanced Vehicle Control
|
Providing OS support for integrated DCU-based platform for autonomous vehicles
|
|
 |
With the advent of Automotive AI, separate ECUs in a vehicle are being merged into a single high performance DCU. Accordingly, we develop additional OS support for SW platform that runs on this DCU. We are currently working on three OS-level techniques for AUTOSAR platform: (1) multicore support for real-time computing, (2) shared memory management for stream processing and (3) three-level monitoring mechanism to increase reliability.
|
6. In-depth Kernel Optimization Techniques
|
Improving interactivity via cross-layer resource control and scheduling for Linux/Android smartphones
|
|
 |
Android smartphones are often reported to suffer from sluggish user interactions due to poor interactivity. This is partly because Android and its task scheduler, the completely fair scheduler (CFS), may incur perceptibly long response time to user-interactive tasks. Particularly, the Android framework cannot systemically favor user-interactive tasks over other background tasks since it does not distinguish between them. Furthermore, user-interactive tasks can suffer from high dispatch latency due to the non-preemptive nature of CFS. To address these problems, we present framework-assisted task characterization and virtual time-based CFS. The former is a cross-layer resource control mechanism between the Android framework and the underlying Linux kernel. It identifies user-interactive tasks at the framework-level, by using the notion of a user-interactive task chain. It then enables the kernel scheduler to selectively promote the priorities of worker tasks appearing in the task chain to reduce the preemption latency. The latter is a cross-layer refinement of CFS in terms of interactivity. It allows a task to be preempted at every predefined period. It also adjusts the virtual runtimes of the identified user-interactive tasks to ensure that they are always scheduled prior to the other tasks in the run-queue when they wake up. As a result, the dispatch latency of a user-interactive task is reduced to a small value.
|
|
Improving interactivity via kernel and middleware optimization for webOS TV
|
|
 |
While analyzing the performance of webOS TV, we found that the TV channel switching time is significantly delayed during the booting process. This delay is caused by CPU resource contention between the channel switching threads and the other threads which perform the boot process. To solve this problem, we propose a cross-layer optimization technique that guarantees the channel switching threads to use sufficient CPU resources using Linux cgroup.
|
|
Reducing energy consumption of a modem via selective packet transmission delaying
|
|
|
|
Most energy-saving mechanisms for an LTE modem rely on a packet transmission delaying technique in that a smartphone attempts to reduce a modem’s energy consumption by delaying transmissions of delay-tolerant packets and piggybacking them onto later packets. However, unconditional packet transmission delaying may lead to unanticipated energy loss of a modem since the exact radio resource control state of a modem is not considered. To address this problem, we propose a mechanism which selectively delays packet transmissions only if such delays are expected to achieve energy savings. In doing so, we make an estimated energy gain model which captures the modem’s energy consumption for transmitting a current packet by considering the modem’s state. Our mechanism consists of three key components: (1) deferrable packet identifier, (2) pattern-based next packet transmission predictor and (3) packet transmission time designator.
|
|
Reducing energy consumption using Predictive On-Demand CPU frequency governor for Linux/Android smartphones
|
|
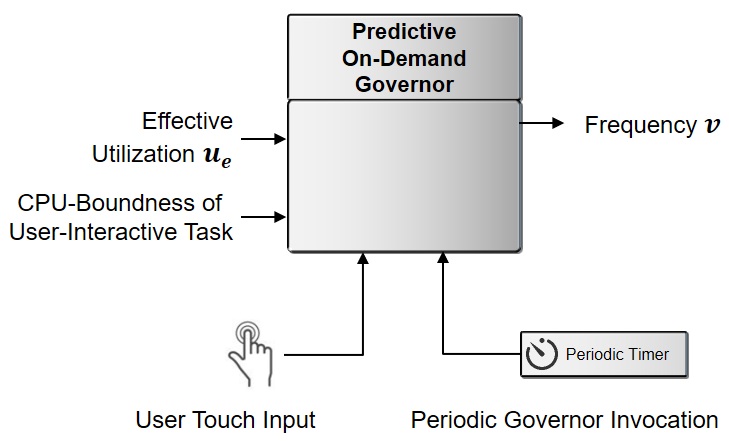 |
Interactive Governor of Android smartphones adjusts CPU frequency according to system utilization and touch inputs. However, Interactive Governor has two limitations. First, it increases CPU when the system utilization is high even if a task that does not affect user responsiveness is being executed. Second, it does not take into account the characteristics of the currently running task. To overcome these limitations, we propose Predictive On-demand governor that adjusts CPU frequency based on the effective utilization and CPU-boundness of user-interactive tasks.
|